Geo algoritme
The problem to be solved
We developed a geo algorithm to solve a problem with the following properties:
- We can obtain certain data based on geo coordinates.
- Before the data request, and afterwards, the completeness of the data set is unknown.
- What is known, is that if the geographical area for which the data was requested is smaller, the data is more accurate
- There are limitations on how many requests we can do
- The resulting data set may be very large
Geo algoritme with heatmaps
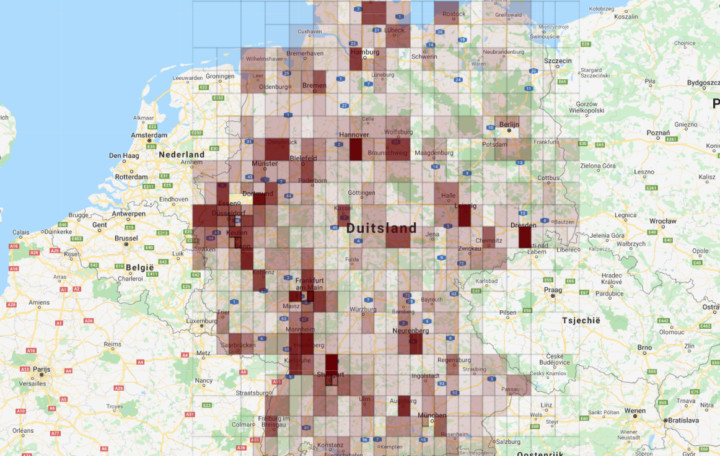
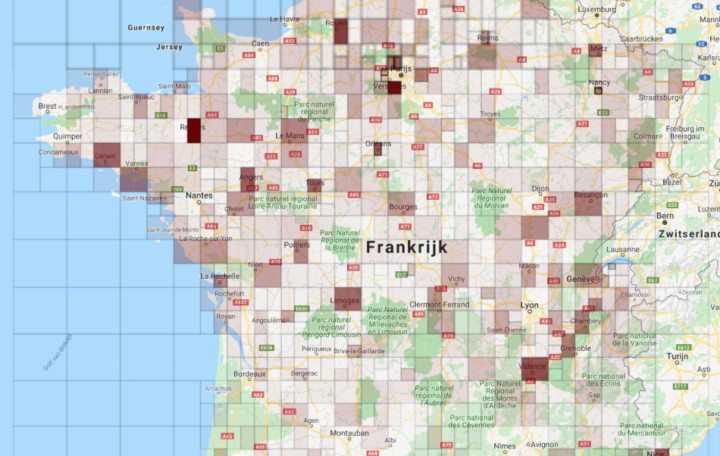
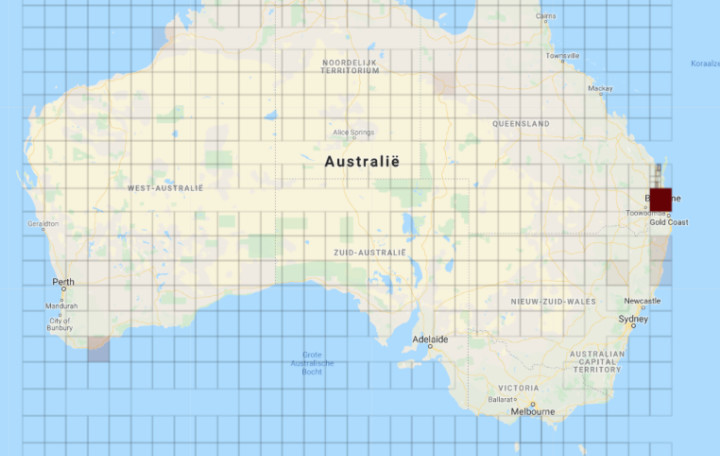
We created an algorithm that internally creates heatmaps based on the data. The algorithm refines the areas into smaller areas. By comparing these areas, it decides if the refinement makes sense and leads to a morge complete dataset, or if the refinement can be rejected.
The result is a list of usable heatmaps with data, varying in size.
Workflow and state machines
Because the algorithm must handle huge amounts of data, and the process may take very long, we cannot execute it in a single process. There would simply not be enough memory, and it would not be fault tolerant.
Hence the process creates many smaller tasks, that can be executed standalone and asynchronously. Each subtask can create it's own subtask. This makes the data aggregation fault tolerant, and restartable.
To control this process, we used de 'workflow' and 'state machine' design patterns. These check the state of the algorithm, and decide what transitions the system can go through.
AWS Certified Devops Engineer
I am currently taking the AWS Certified DevOps Engineer course to enhance my knowledge in infrastructure automation and CI/CD.
AWS migration
Progress update on the current AWS migration project
Load en Stress tests
Test your cloud infrastructure with K6

Gobot RPI simulator
A GPIO pin simulator for RPI written in Golang

Reactions Craft CMS plugin
A new Craft CMS plugin to add Facebook style reactions
Vertaal component
A translation component in Symfony, with API and control panel.